AI Engineering
AI, engineered properly.
We design and build AI into real software, whatever the industry, whatever the problem. If there is unstructured information, repetitive judgment, or a workflow that should be smarter, there is engineering work worth doing properly.
What AI engineering is
A model is one component. The engineering is everything around it: the data architecture that feeds it, the prompts and schemas that constrain it, the retrieval that grounds it in real information, the evaluation that measures it, and the fallbacks that catch it when it is wrong.
Most AI work stops at the demo. Production means the system handles messy data, edge cases, latency budgets, cost at scale, and the inevitable moment when the model confidently returns something wrong.
The output is only as good as the engineering under it.
The model is one part.
The engineering is everything else.
The engineering
Six disciplines, one system.
The right model for the job
Frontier models: Claude, GPT-class, open-source where privacy or cost demands it, accessed through APIs and chosen per task. Capability at the problem, cost at expected volume, and data residency for the jurisdiction. We do not have a brand preference; we have a decision framework.

Guaranteed shape, every time
Models constrained by JSON schemas, including function calling, typed parameters, enum constraints, so every response has a shape a system can consume. Missing data is declared as unknown; the system never invents clinical or financial detail.
Meaning as numbers
Text converted to vectors and queried by meaning instead of keywords; cosine distance over an embedded corpus finds what matches the intent of a question, even when it shares no words with it.
Grounded in your data
Answers drawn from the business's own documents, records, and knowledge, retrieved, assembled into context, reranked for relevance, and cited back to the source, not model opinion. The retrieval architecture decides what the model sees, how much, and in what order; that is what makes an answer something the business can trust and verify.

Measured before it ships
Every AI feature is evaluated against the client's own data before it reaches users: a golden set of known-correct outputs, accuracy and regression testing, latency budgets, and cost per task measured as a system, not optimized in isolation.

Where AI sits in real software
AI features live inside applications: queues, permissions, human-approval steps, monitoring, and audit trails. Fallback chains define what happens when a model is slow, wrong, or down. Data residency is decided in writing before anything is built: what reaches a model, what stays local, what gets logged.

How we choose a model
An engineering decision, not a brand loyalty.
Can it do the job?
Long-context reasoning, classification, extraction, or generation; the task defines the candidate list, not the logo.
Fast enough to use?
A real-time field tool and an overnight batch pipeline have different budgets; both are measured, not assumed.
Realistic at volume?
Cost per task at expected volume, projected forward; the economics are part of the architecture.
Where does data go?
Canadian-hosted or privacy-critical workloads constrain the candidate list before capability is even scored.
"When a better model arrives, your system is ready for it. The architecture is built to evolve."
What we measure before launch
Tested like infrastructure, because it is.
Measured against real inputs with verified outputs before any user sees a result.
The slowest experience that ships is defined in the Blueprint, then held to.
Unit economics at expected volume, reported plainly in the quote.
Fallbacks, human approval, and what the user sees when the model fails, documented, not discovered.
Selected work
All work has been anonymized to protect clients.
Development intelligence platform
End-to-end site intelligence for land development: a spatial compliance engine that checks every bylaw rule against a project in seconds, AI-drafted planning rationale and variance justification, and daily monitoring of title, permits, and regulatory changes with alerts ranked by financial impact.
On a single marina project, the developer estimated $250,000 in avoided costs.
View project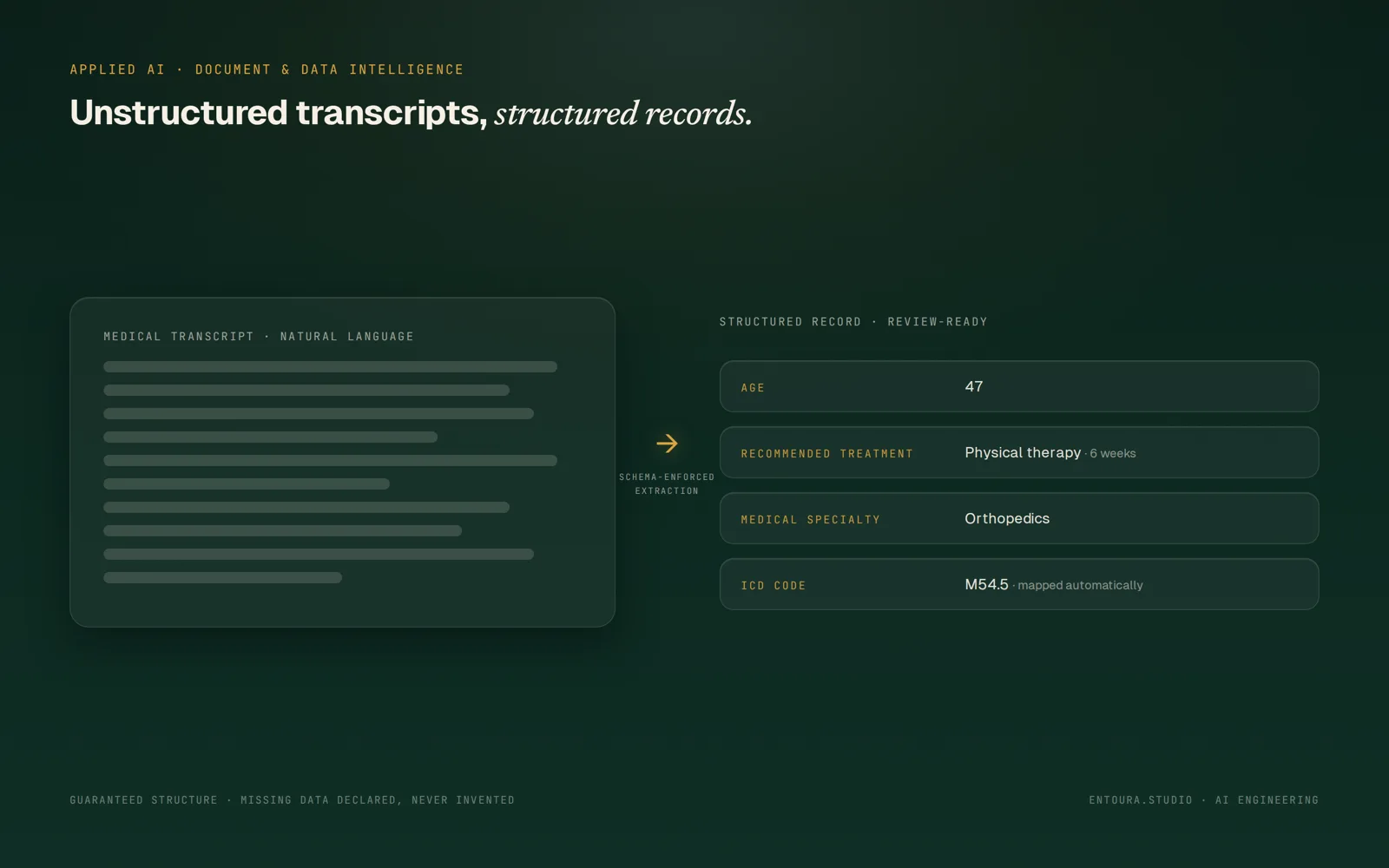
Medical transcription intelligence
Unstructured medical transcripts processed into structured, usable data — extraction and interpretation of vital information, reducing administrative load on healthcare professionals.
View projectWondering what this looks like inside your business?
Start with the Blueprint™How it works
Four steps. The Blueprint is the start.
The Blueprint states in writing what reaches a model, what stays local, and what gets logged, before development begins.
Discovery call
A focused conversation about the workflow and whether AI belongs in it. Free, 30 minutes.
Blueprint™
The development-ready plan. Defines what reaches a model, what stays local, and what gets logged, in writing, before code.
Build
Weekly working previews against real data. The AI feature is evaluated, not just demonstrated.
Handoff
You own and control the software. Monitoring, documentation, and a clean operational surface, managed for you with no lock-in.
The operating system these build toward
AI engineering is the intelligence inside a connected operating system for your business.
Read the full guideStart a project
Ready to build? Let's talk.
Start with a free 30-minute call. We scope the first useful version and deliver a fixed quote.
30 minutes · a clear answer either way
Frequently asked
Do we need our own data to start?
Not necessarily. Some AI features work with public data, general-purpose models, or data the system collects over time. The Blueprint defines what data the system needs, where it comes from, and whether you need to collect or prepare it before development begins.
Which models do you use?
Whichever model fits the job. Claude for complex reasoning, GPT-class for structured extraction, open-source where cost or residency demands it. The Blueprint specifies the model, the rationale, and the swap path if a better option arrives.
Where does our data go?
Decided in writing during the Blueprint. Application data stays in Canada. What gets sent to a model API, what stays local, and what gets logged is documented and agreed before development starts.
What if the AI is wrong?
Defined behaviour: fallbacks, confidence thresholds, human review queues, and graceful degradation. The system is built to handle model errors as a normal operational condition.
What does it cost?
Scoped in the Blueprint. The Blueprint produces a fixed quote for the full build. Ongoing model costs are broken out plainly in the quote.
Can this run privately on our own data?
Yes, where the task warrants it. Open-source models can be deployed on infrastructure the client controls. The Blueprint evaluates both paths.
What happens when better models come out?
The architecture isolates the model so it can be swapped. New models get evaluated against the golden set. Improvements are adopted based on measured performance, not announcements.