Medical transcription intelligence
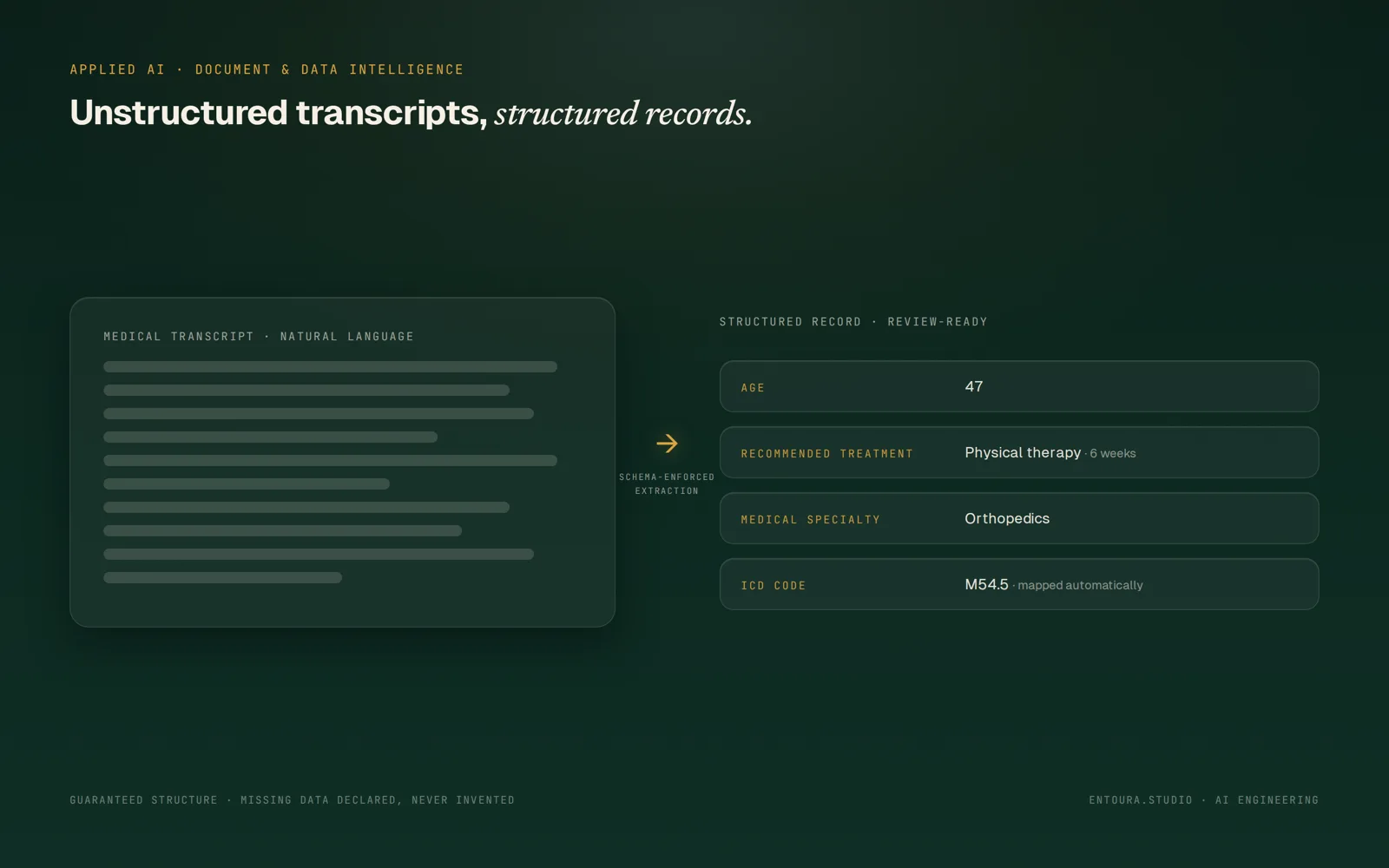
Unstructured medical transcripts processed into structured, usable data — extraction and interpretation of vital information, reducing administrative load on healthcare professionals.
Healthcare
Document and data intelligence
OpenAI API · Structured outputs · ICD-10 mapping · pandas
Applied project
The problem
Medical transcriptions hold the information a clinic runs on — ages, treatments, procedures — locked inside free-form natural language. Extracting it by hand is administrative time taken from patient care.
What was engineered
Schema-enforced extraction
The model is constrained by a defined schema (function calling), so every record returns the same fields in the same shape: patient age and recommended treatment or procedure.
Unknown over invented
Missing information is declared as unknown rather than guessed — the system is built to never invent clinical data.
Automated ICD coding
A second stage maps each extracted treatment to its ICD codes, run at low temperature for consistency, and the results assemble into a clean, analysis-ready dataset.
From the build
tools = [{
class="code-string">"type": class="code-string">"function",
class="code-string">"function": {
class="code-string">"name": class="code-string">"extract_medical_data",
class="code-string">"description": class="code-string">"Return the patient's age and "
class="code-string">"recommended treatment from a transcription.",
class="code-string">"parameters": {
class="code-string">"type": class="code-string">"object",
class="code-string">"properties": {
class="code-string">"age": {class="code-string">"type": class="code-string">"integer"},
class="code-string">"recommended_treatment": {class="code-string">"type": class="code-string">"string"},
},
},
},
}]
class=class="code-string">"code-comment"># Schema-enforced output: every record returns the same
class=class="code-string">"code-comment"># fields. Missing information is declared as unknown —
class=class="code-string">"code-comment"># the system never invents clinical data.Why it matters
The pattern generalizes to any document-heavy operation: schema-enforced extraction, explicit handling of missing data, and automated coding against an external standard. Unstructured language in, dependable records out.
Stack
All work has been anonymized to protect clients.
Start a project
Ready to build? Let's talk.
Start with a free 30-minute call. We scope the first useful version and deliver a fixed quote.
30 minutes · a clear answer either way